Published: 13-07-2016
Overview
Now makeit-processor kinda works it would be nice to be able to save and load code, not re-enter it the whole time. What I wanted to do was have a Git repo style backend. A CAD/CAM project can look a lot like a repo, so it makes sense. Git repos that aren't just code but that represent a physical objects. The idea is that each CAD/CAM project/model is it's own repo and all the files represent parts, which are assembled. The same goes for plugins. The readme is the projects documentation, just like with programming projects. Projects are designed from the start with manufacturing in mind and so each part has it's CAM section.
Git
It's fairly simple to do the basics in Git. Settings up a git server looks and probably is pretty easy, but how does one get data to and from the server without using git on another machine? The first option is to call the Git CLI straight from from node. Hang on, how does Github do it? Check this video out. Sooo, libgit2 and and a node binding, nodegit it is. Stick them on a server together with node plus express, and maybe there's a RESTful Git based filestore somewhere in there.
Getting started
'makeit-filestore' could and should be a separate server to keep things clean and modular. To get started though it makes sense just to use nodegit on the makeit-design server with a local repository. Once things look like they work okay it will be fleshed out to it's own service.
Nodegit
Installing nodegit was easy:
npm install --save nodegit
Getting repo file/folder paths
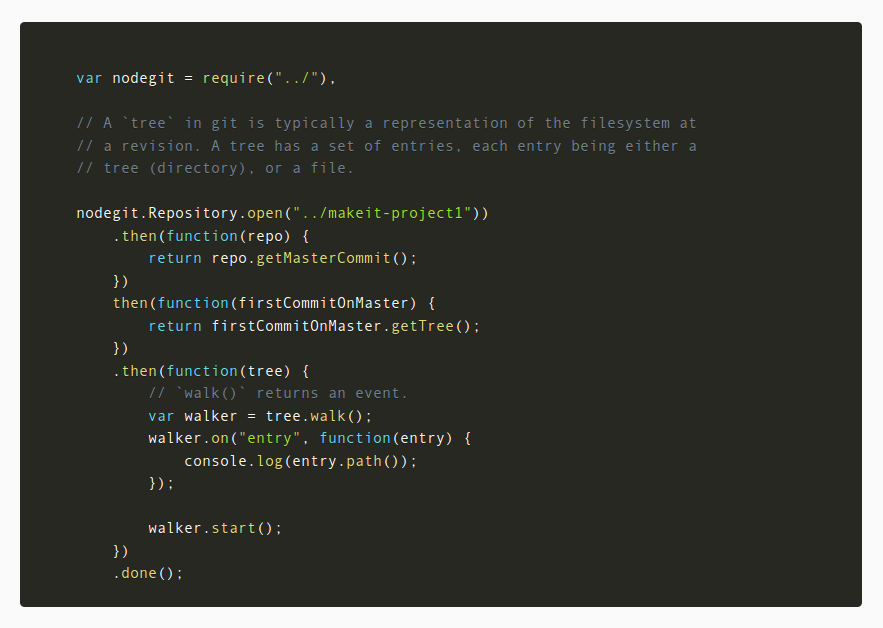
With a new repo set up to test it out here it goes. There are a good number of examples in the Nodegit examples folder. The walk-tree example a good one to start with. This grabs the latest commit on the master branch and walks the tree, logging the paths as it goes.
var nodegit = require("../"),
// A `tree` in git is typically a representation of the filesystem at
// a revision. A tree has a set of entries, each entry being either a
// tree (directory), or a file.
nodegit.Repository.open("../makeit-project1"))
.then(function(repo) {
return repo.getMasterCommit();
})
then(function(firstCommitOnMaster) {
return firstCommitOnMaster.getTree();
})
.then(function(tree) {
// `walk()` returns an event.
var walker = tree.walk();
walker.on("entry", function(entry) {
console.log(entry.path());
});
walker.start();
})
.done();
For some weird reason the tree walker is an event emitter, rather than a promise like every other function! So to get all the file paths together before moving through the chain, it had to be wrapped in a promise like so:
var nodegit = require('nodegit');
nodegit.Repository.open("../../makeit-project1")
.then(function(repo) {
return repo.getMasterCommit();
})
.then(function(firstCommitOnMaster) {
return firstCommitOnMaster.getTree();
})
.then(function(tree) {
return new Promise(function (resolve, reject) {
var files = [];
var walker = tree.walk();
walker.on("entry", function(new_tree) {
files.push(new_tree.path());
});
walker.on("end", function (trees) {
resolve(files)
})
walker.start();
});
})
.then(function (files) {
console.log(files);
})
.done()
// [ 'readme.md',
// 'sqaure.cam.js',
// 'square.cad.js',
// 'sub1/circle.cad.js',
// 'sub1/circle.cam.js' ]
Getting the blobs
You could get all the blobs fairly easily while finding the file paths, cue array of promises. It might not be a great idea to grab everything at the same time though even if it does cut the number of future round trips down. How often would you need all the blobs, not very. So, some code to get the file contents separately, in string form:
var _entry;
nodegit.Repository.open('../../makeit-project1')
.then(function(repo) {
return repo.getMasterCommit();
})
.then(function(firstCommitOnMaster) {
return firstCommitOnMaster.getEntry('readme.md');
})
.then(function (entry) {
_entry = entry;
return entry.getBlob()
})
.then(function(blob) {
return blob.toString()
})
}
So far all the repos and paths are hard coded in, but these are now to be swapped for variables and placed in functions, ready to be exported. The filestore functions are then called on API requests which look like this:
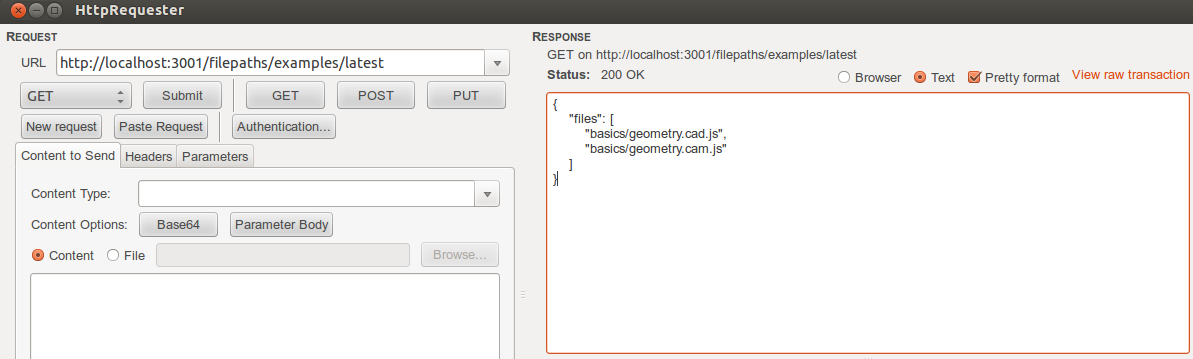
Getting all file paths for a repo at a commit:
GET http://localhost:3001/filepaths/*repo*/*commit*
Example:
GET http://localhost:3001/filepaths/examples/latest
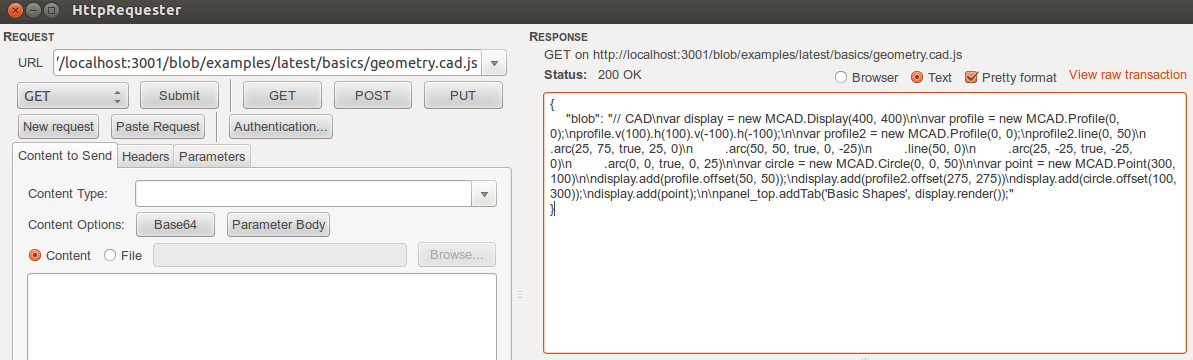
Getting blob for a file path in repo at commit:
GET http://localhost:3001/blob/*repo*/*commit*/*file_path*
Example
GET http://localhost:3001/blob/examples/latest/basics/geometry.cad.js
The file paths contains forward slashes and is grabbed using regex instead of a standard variable id. Here latest refers to the last commit on the master branch. Branches are not handled yet. No state is held on the server so branches would need to be specified explicitly. After setting up an examples repo with basic geometry CAD and CAM files it's time to make a request:
Angular Http Request
All seemed to be working so it's time to grab angular and update the filestore service to use these files instead of dummy ones. The filestore service now has method that looks like this:
getFilePaths(repo, commit) {
var api_url = `filepath/${repo}/${commit}`
return this.http.get(api_url)
.map(function (res: Response) {
let body = res.json();
return body.files || []
})
.catch(function (error) {
console.log(error);
return Observable.throw(error);
})
}
And the component has a call to it that looks like:
this.filestoreService.getFilePaths('examples', 'latest')
.subscribe(
(paths) => {
this.directory = paths;
console.log(paths);
},
(error) => { console.log(error) }
);
And the rest
Now the pipeline of requests seems to work with nodegit/express/angular the API can start taking shape.
Multiple repos
The design stipulates that each CAM/CAM project is it's own repo. This means that each user might have more than one repo. Each user will therefore need a directory for all their repos.
References